Rhawn Gabriel Joseph, Ph.D.
BrainMind.com
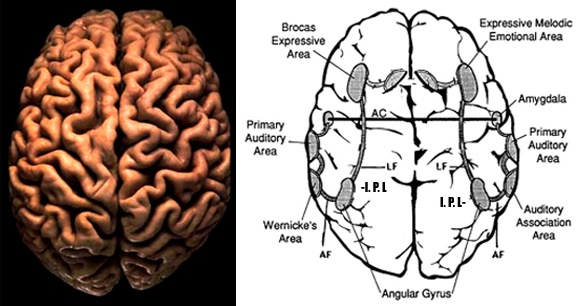
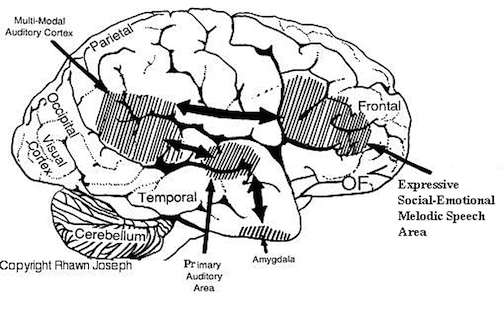
FUNCTIONAL NEUROANATOMY OF THE AUDITORY ASSOCIATION AREAS
The right and left temporal lobe are functionally lateralized, with the left being more concerned with non-emotional language functions, including, via the inferior-medial and basal temporal lobes reading and verbal (as verbal-visual) memory. For example, as determined based on functional imaging, when reading and speaking the left posterior temporal lobe becomes highly active, due, presumably to its involvement in lexical processing (Binder et al., 2004; Howard et al., 199). The superior temporal lobe (and supramarginal gyrus) also becomes more active when reading aloud than when reading silently (Bookheimer, et al., 1995), and becomes active during semantic processing as does the left angular gyrus (Price, 1997). These same temporal areas are activated during word generation (Shaywitz, et al., 1995; Warburton, et al., 1996), and sentence comprehension tasks (Bottini, et al., 2004; Fletcher et al., 1995). and (in conjunction with the angular gyrus) becomes highly active when retrieving the meaning of words during semantic processing and semantic decision tasks (Price, 1997). Likewise, single cell recordings from the auditory areas in the temporal lobe demonstrate that neurons become activated in response to speech, including the sound of the patient's own voice (Creutzfeldt, et al., 1989).
By contrast, the right is more concerned with perceiving emotional and melodic auditory signals (Evers et al., 1999; Parsons & Fox, 1997; Ross, 1993), and is dominant for storing and recalling emotional and visual memories (Abrams & Taylor, 2009; Cimino, et al. 1991; Cohen, Penick & Tarter, 2014; Deglin & Nikolaenko, 1975; Kimura, 1963; Shagass et al.,2009; Wexler, 1973). The right temporal lobe becomes highly active when engage in interpreting the figurative aspects of language (Bottini et al., 2004).
However, there is considerable functional overlap and these structures often become simultaneously activated when performing various tasks. For example, as based on functional imaging, when reading, the right posterior temporal cortex also becomes highly active (Bookheimer, et al., 1995; Bottini et al., 2004; Price, et al., 1996), and when making semantic decisions (involving reading words with similar meanings), there is increased activity bilaterally (Shaywitz, et al., 1995).
Presumably, in part, both temporal lobes become activated when speaking and reading, due to the left temporal lobe's specialization for extracting the semantic, temporal, sequential, and the syntactic elements of speech, thereby making language comprehension possible. By contrast, the right temporal lobe becomes active as it attempts to perceive, extract and comprehend the emotional (as well as the semantic) and gestalt aspects of speech and written language.
AUDITORY NEOCORTEX
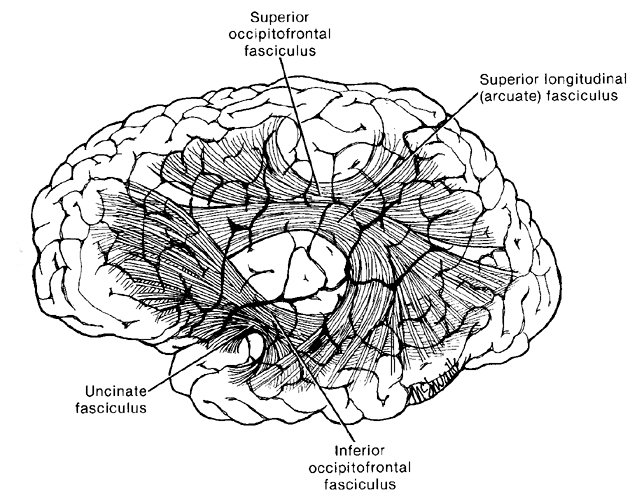
Although the various cytoarchitectural functional regions are not well demarcated via the use of Brodmann's maps, it is possible to very loosely define the superior-temporal and anterior-inferior and anterior middle temporal lobes as auditory cortex (Pandya & Yeterian, 1985). These regions are linked together by local circuit (inter-) neurons and via a rich belt of projection fibers which include the arcuate and inferior fasciculus which project in a anterior-inferior and posterior-superior arc innervating (inferiorally) the amygdala and entorhinal cortex (Amaral et al., 1983) and posteriorally the inferior parietal lobule--as is evident based on brain dissection. It is also via the arcuate and inferior fasciculus that the inferior temporal lobe, entorhinal cortex (the "gateway to the hippocampus") as well as the amygdala (receive from) and transfer complex auditory information to the primary and secondary auditory cortex which simultaneously receives auditory input from the medial geniculate of the thalamus, the pulvinar, and (sparingly) the midbrain (Amaral et al., 1983; Pandya & Yeterian, 1985). As will be detailed below, it is within the primary and neocortical auditory association areas where linguistically complex auditory signals are analyzed and reorganized so as to give rise to complex, grammatically correct, human language.
It is noteworthy that immediately beneath the insula and approaching the auditory neocortex is a thick band of amygdala-cortex, the claustrum. Over the course of evolution the claustrum apparently split off from the amygdala due to the expansion of the temporal lobe and the passage of additional axons coursing throughout the white matter (Gilles et al., 1983) including the arcuate fasciculus. Nevertheless, the claustrum maintains rich interconnections with the amygdala, the insula, and to some extent, the auditory cortex (Gilles et al., 1983). This is evident from dissection of the human brain which reveals that the fibers of the arcuate fasciculus do not merely pass through this structure (breaking it up in the process) but sends and receives fibers from it.
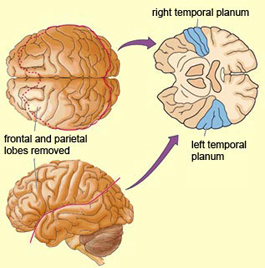
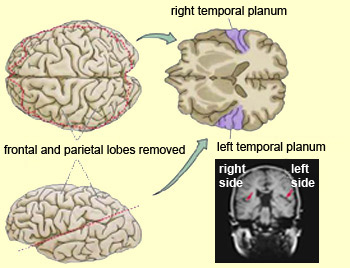
CORTICAL ORGANIZATION
The functional neural-architecture of the auditory cortex is quite similar to the somesthetic and visual cortex (Peters & Jones, 1985). That is, neurons in the same vertical columns have the same functional properties and are activated by the same type or frequency of auditory stimulus. The auditory cortex, therefore, is basically subdivided into discrete columns which extend from the white matter (layers VII/6b) to the pial surface (layer I). However, although most neurons in a single column receive excitatory input from the contralateral ear, some receive input from the ipsilateral ear which may exert excitatory or inhibitory influences so as to suppressed, within the same column, input from itself or from the contralateral ear (Imig & Brugge, 1978). These interactions have been referred to as summation interaction (excitatory/excitatory) and suppression interaction (inhibitory/inhibitory, inhibitory/excitatory).
Moreover, some columns tend to engage in excitatory summation, whereas others tend to engage in inhibitory suppression (Imig & Brugge, 1978)--a process that would contribute to the focusing of auditory attention and the elimination of neural noise thereby promoting the ability to selectively attend to motivationally significant environmental and animal sounds including human vocalizations (Nelken et al., 1999).
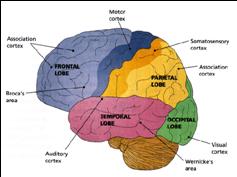
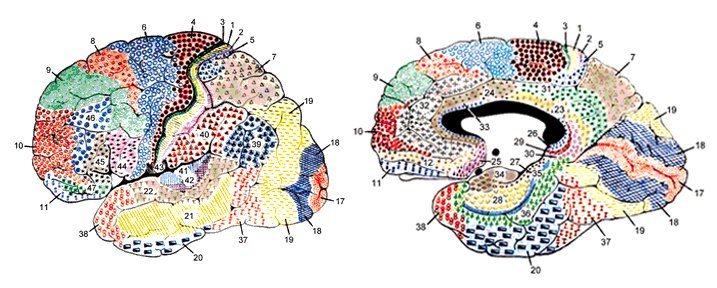
Among humans, the primary auditory neocortex is located on the two transverse gyri of Heschl, along the dorsal-medial surface of the superior temporal lobe. The center most portion of the anterior transverse gyri contains the primary auditory receiving area (Broadman's area 41) and neocortically resembles the primary visual (area 17) and somesthetic cortices (area 3). The posterior transverse gyri consists of both primary and association cortices (areas 41 and 42 respectively). The major source of auditory input is derived from the medial geniculate thalamic nucleus as well as the pulvinar (which also provides visual input).
Heschl's gyri is especially well developed and no other species has a Heschl's gyrus that as prominent as is the case with humans (Yousry et al., 1995). In fact, some individuals appear to posses multiple Heschl gyri--though the significance of this is not clear. However, it has been reported that this may be a reflection of genetic disorders, learning disabilities, and so on (see Leonard, 1996).
In over 80-90% of right handers and in over 50% to 80% of left handers, the left hemisphere is dominant for expressive and receptive speech (Frost et al., 1999; Pujol, et al., 1999). In humans, the auditory cortex including Wernicke's (i.e. the planum temporale) is generally larger on the left temporal lobe (Geschwind & Levitsky, 1968; Geschwind & Galaburda 1985; Habib et al. 1995; Wada et al., 1975; Witelson & Pallie, 1973). Specifically, as originally determined by Geschwind & Levitsky (1968), the planum temporal is larger in the left hemisphere in 65% of brains studied, is larger on the right in 25%, whereas there is no difference in 10%. Geschwind, Galaburda and colleagues argue that the larger left planum temporale is a significant factor in the establishment of left hemisphere dominance for language.
AUDITORY TRANSMISSION FROM THE COCHLEA TO THE TEMPORAL LOBE
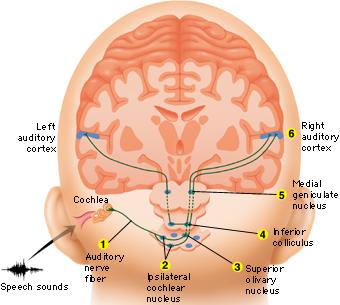
Within the cochlea of the inner ear are tiny hair cells which serve as sensory receptors. These cells give rise to axons which form the cochlear division of the 8th cranial nerve; i.e. the auditory nerve. This rope of fibers exits the inner ear and travels to and terminates in the cochlear nucleus which overlaps and is located immediately adjacent to the vestibular-nucleus from which it evolved within the brainstem (see chapter 5).
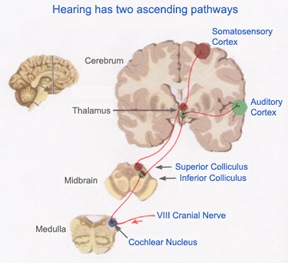
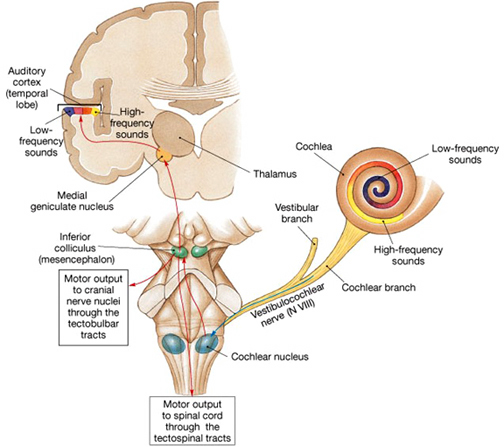
Among mammals once auditory stimuli are received in the cochlear nucleus there follows a series of transformations as this information is relayed to various nuclei, i.e., the superior olivary complex, the nucleus of the lateral lemniscus of the brainstem, the midbrain inferior colliculus and medial geniculate nucleus of the thalamus as well as the amygdala (which extracts those features which are emotionally or motivationally significant), and cingulate gyrus (Carpenter 1991; Devinksy et al. 1995; Edeline et al. 2010; Parent 1995). Auditory information is then relayed from the medial geniculate nucleus of the thalamus as well as via the amygdala (through the inferior fasciculus) to Heschl's gyrus, i.e. the primary auditory receiving area (Brodmann's areas 41 & 42) located within the superior temporal gyrus and buried within the depths of the Sylvian fissure.
Here auditory signals undergo extensive analysis and reanalysis and simple associations are established. However, by time they have reached the neocortex, auditory signals have undergone extensive analysis by the medial thalamus, amygdala, and the other ancient structures mentioned above.
As noted, unlike the primary visual and somesthetic areas located within the neocortex of the occipital and parietal lobes which receive signals from only one half of the body or visual space, the primary auditory region receives some input from both ears, and from both halves of auditory space (Imig & Adrian, 1977). This is a consequence of the considerable interconnections and cross-talk which occurs between different subcortical nuclei as information is relayed to and from various regions prior to transfer to the neocortex. Predominantly, however, the right ear transmits to the left cerebral neocortex and vice versa.
Although the majority of auditory neurons respond to auditory stimuli, approximately 25% also respond to visual stimuli, particularly those in motion. In fact, Penfield and Perot (1963) were able to trigger visual responses from stimulation in the superior temporal lobe. In addition, these neurons are involved in short-term memory, as lesions to the superior temporal lobe can induce short-term memory deficits (Heffner & Heffner, 1986).
Conversely, electrical stimulation not only induces visual responses, but complex auditory responses. Penfield and Perot (1963) report that electrical stimulation can produce the sound of voices, and the hearing of music. These neurons will also respond, electrophysiologically, to the sound of human voices, including the patient's own speech (Creutzfeldt, et al., 1989). Conversely, injury to the left and right superior temporal lobe can result in an inability to correctly perceive or hear complex sounds; a condition referred to as pure word deafness, and if limited to the right ear, agnosia for environmental and musical sounds (see below). In fact, right temporal injuries can disrupt the ability to remember musical tunes or to create musical imagery (Zatorre & Halpen, 1993).
AUDITORY RECEIVING AREA NEUROANATOMICAL-FUNCTIONAL ORGANIZATION.
The primary auditory area is tonotopically organized (Edeline et al. 2010; Merzenich & Brugge, 1973; Pantev et al. 1989; Woolsey & Fairman, 1946), such that different auditory frequencies are progressively anatomically represented. In addition, there is evidence to suggest that the auditory cortex is also "cochleotopically" organized (Swarz & Tomlinson 2010). Specifically, high frequencies are received and analyzed in the anterior-medial portions and low frequencies in the posterior-lateral regions of the superior temporal lobe (Merzenich & Brugge, 1973). In addition, the primary auditory cortex processes and perceives pitch and intensity, as well as modulations in frequency. Primary auditory neurons are especially responsive to the temporal sequencing of acoustic stimuli (Wolberg & Newman, 1972).
Moreover, the auditory cortex appears to be organized so as to detect tones in noise, i.e. the non-random structure of natural sounds, which enables it to selectively attend to environmental and animal sounds including human vocalizations (Nelken et al., 1999). In fact, these same neural fields can be activated by sign language, that is, among the congenitally deaf (Nishimura et al., 1999).
Some neurons are also specialized to perceive specific-specific calls (Hauser, 1997) or the human voice (Crutzfeldt et al., 1989). This has been determined by single unit recording. Some neurons will react to the patient's voice, whereas yet others will selectively respond to a particular (familiar) voice or call, but not to others--which in regard to voices, indicates that these cells (or neural assemblies) have engaged in learning.
Auditory neurons in fact, display neurplasticity in response to learning as well as injury. For example, not only due auditory synapses display learning-induced changes, but auditory neurons can be classically conditioned so as to form associations between stimuli, such that if a neutral stimulus is paired with a noxious stimulus, the neurons response properties will be greatly altered (Weinberger, 1993).
These neurons also display neuroplasticity in response to injury and loss of hearing. For example, due to cochlear or peripheral hearing loss, neurons that no longer receive high frequency auditory input, begin to respond instead to middle frequencies (Robertson & Irvine, 1989). In fact, in response to complete loss of hearing, such as congenital deafness, these neurons may cease to respond to auditory input and may instead respond to body language, such as the signing used by the deaf (Nishimura et al., 1999).
FILTERING, FEEDBACK & TEMPORAL-SEQUENTIAL REORGANIZATION
The old cortical centers located in the midbrain and brain stem evolved long before the appearance of neocortex and have long been adapted and specialized for performing a considerable degree of information analysis (Buchwald et al. 1966). This is evident from observing the behavior of reptiles and amphibians where auditory cortex is either absent or minimally developed.
Moreover, many of these old cortical nuclei also project back to each other such that each subcortical structure might hear and analyze the same sound repeatedly (Brodal 1981; Pandya & Yeterian, 1985). In this manner the brain is able heighten or diminish the amplitude of various sounds via feedback adjustment (Joseph, 1993; Luria, 1980). In fact, not only is feedback provided, but the actual order of the sound elements perceived can be rearranged when they are played back.
This same process continues at the level of the neocortex which has the advantage of being the recipient of signals that have already been highly processed and analyzed (Buchwald et al. 1966; Edeline et al. 2010; Scharz & Tomlinson 2010). Primary auditory neurons are especially responsive to the temporal sequencing of acoustic stimuli (Wolberg & Newman, 1972). It is in this manner, coupled with the capacity of auditory neurons to extract non-random sounds from noise, that language related sounds begin to be organized and recognized (e.g. Nelken et al., 1999; Scwazrz & Tomlinson 2010).
For example, neurons located in the primary auditory cortex can determine and recognize differences and similarities between harmonic complex tones and demonstrated auditory response patterns that vary in response to lower and higher frequency and to specific tones (Nelken et al. 1999; Scwarz & Tomlinson 2010). Some display "tuning bandwithdts" for pure tones, whereas others are able to identify up to seven components of harmonic complex tones. In this manner, pitch can also be discerned (e.g. Pantev et al. 1989). Sustained Auditory Activity.
One of the main functions of the primary auditory neocortical receptive area appears to be the retention of sounds for brief time periods (up to a second) so that temporal and sequential features may be extracted and discrepancies in spatial location identified; i.e. so that we can determine from where a sound may have originated (see Mills & Rollman 1980). This prolonged activity, presumably also allows for additional processing and so that comparisons to be made with sounds that were just previously received and those which are just arriving. Hence, as based on functional imaging, the left temporal lobe becomes increasingly active as word length increases (Price, 1997), due presumably to the increased processing necessary.

Moreover, via their sustained activity, these neurons are able to prolong (perhaps via a perseverating feedback loop with the thalamus) the duration of certain sounds so that they are more amenable to analysis--which may explain why activity increases in response to unfamiliar words and as word length increases (Price, 1997). In this manner, even complex sounds can be broken down into components which are then separately analyzed. Hence, sounds can be perceived as sustained temporal sequences. It is perhaps due to this attribute that injuries to the superior temporal lobe result in short-term auditory memory deficits as well as disturbances in auditory discrimination (Hauser, 1997; Heffner & Heffner, 1986).
Although it is apparent that the auditory regions of both cerebral hemispheres are capable of discerning and extracting temporal-sequential rhythmic acoustics (Milner, 1962; Wolberg & Newman, 1972), the left temporal lobe apparently contains a greater concentration of neurons specialized for this purpose as the left half of the brain is clearly superior in this capacity (Evers et al., 1999).
For example the left hemisphere has been repeatedly shown to be specialized for sorting, separating and extracting in a segmented fashion, the phonetic and temporal-sequential or linguistic-articulatory features of incoming auditory information so as to identify speech units. It is also more sensitive to rapidly changing acoustic cues be they verbal or non-verbal as compared to the right hemisphere (Shankweiler & Studdert-Kennedy, 1967; Studdert-Kennedy & Shankweiler, 1970). Moreover, via dichtoic listening tasks, the right ear (left temporal lobe) has been shown to be dominant for the perception of real words, word lists, numbers, backwards speech, morse code, consonants, consonant vowell syllables, nonsense syllables, the transitional elements of speech, single phonemes, and rhymes (Blumstein & Cooper, 2014; Bryden, 1967; Cutting, 2014; Kimura, 1961; Kimura & Folb, 1968; Levy, 2014; Mills & Rollman, 2009; Papcunm et al., 2014; Shankweiler & Studert-Kennedy, 1966, 1967; Studdert-Kennedy & Shankweiler, 1970). In addition, and as based on functional imaging, activity significantly increases in the left hemisphere during language tasks (Nelken et al., 1999; Nishimura et al., 1999), including reading (Binder et al., 2004; Price, 1997).
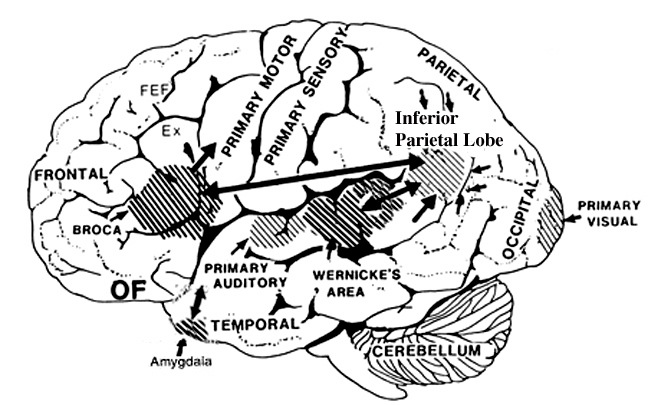
In part the association of the left hemisphere and left temporal lobe with performing complex temporal-sequential and linguistic analysis is due to its interconnections with the inferior parietal lobule (see chapters 6, 11)--a structure which also becomes highly active when reading and naming (Bookheimer, et al., 1995; Menard, et al., 1996; Price, 1997; Vandenberghe, et al., 1996) and which acts as a phonological storehouse that becomes activated during short-term memory and word retrieval (Demonet, et al., 2004; Paulesu, et al., 1993; Price, 1997).
As noted in chapters 6, 11, the inferior parietal lobule is in part an outgrowth of the superior temporal lobe but also consists of somesthetic and visual neocortical tissue. However, the inferior parietal lobule also acts to impose temporal sequences on incoming auditory, as well as visual and somesthetic stimuli, and also serves to provide (via its extensive interconnections with surrounding brain tissue) and integrate related associations thus making complex and grammatically correct human language possible (chapters 5, 11).
However, the language capacities of the left temporal lobe are also made possible via feedback from "subcortical" auditory neurons, and via sustained (vs diminished) activity and analysis. That is, because of these "feedback" loops the importance and even order of the sounds perceived can be changed, filtered or heightened; an extremely important development in regard to the acquisition of human language (Joseph, 1993; Luria, 1980). In this manner sound elements composed of consonants, vowels, and phonemes and morphemes can be more readily identified, particularly within the auditory neocortex of the left half of the brain (Cutting 2014; Shakweiler & Studdert-Kennedy 1966, 1967; Studdert-Kennedy & Shankweiler, 1970).
For example, normally a single phoneme may be scattered over several neighboring units of sounds. A single sound segment may in turn carry several successive phonemes. Therefore a considerable amount of reanalysis, reordering, or filtering of these signals is required so that comprehension can occur (Joseph 1993). These processes, however, presumably occurs both at the neocortical and old cortical level. In this manner a phoneme can be identified, extracted and analyzed and placed in its proper category and temporal position (see edited volume by Mattingly & Studdert-Kennedy, 1991 for related discussion).
Take, for example, three sound units, "t-k-a," which are transmitted to the superior temporal auditory receiving area. Via a feedback loop the primary auditory area can send any one of these units back to the thalamus which again sends it back to the temporal lobe thus amplifying the signal and/or which allows for rearranging their order, "t-a-k," or "K-a-t." A multitude of such interactions are in fact possible so that whole strings of sounds can be arranged or rearranged in a certain order (Joseph 1993). Mutual feed back characterizes most other neocortical-thalamic interactions as well, be it touch, audition, or vision (Brodal 1981; Carpenter 1991; Parent 1995).
Via these interactions and feedback loops sounds can be repeated, their order can be rearranged, and the amplitude on specific auditory signals can be enhanced whereas others can be filtered out. It is in this manner, coupled with experience and learning (Edeline et al. 2010; Diamond & Weinberger 1989) that fine tuning of the nervous system occurs so that specific signals are attended to, perceived, processed, committed to memory and so on. Indeed, a significant degree of plasticity in response to experience as well as auditory filtering occurs throughout the brain not only in regard to sound, but visual and tactual information as well (Greenough et al. 1987; Hubel & Wiesel, 1970; Juliano et al. 2004). Moreover, the same process occurs when organizing words for expression.
This ability to perform so many operations on individual sound units has in turn greatly contributed to the development of human speech and language. For example, the ability to hear human speech requires that temporal resolutions occur at great speed so as to sort through the overlapping and intermixed signals being perceived. This requires that these sounds are processed in parallel, or stored briefly and then replayed in a different order so that discrepancies due to overlap in sounds can be adjusted for (see Mattingly & Studdert-Kennedy, 1991 for related discussion), and this is what occurs many times over via the interactions of the old cortex and the neocortex. Similarly, when speaking or thinking, sound units must also be arranged in a particular order so that what we say is comprehensible to others and so that we may understand our own verbal thoughts.
HEARING SOUNDS & LANGUAGE
Humans are capable of uttering thousands of different sounds all of which are easily detected by the human ear. And yet, although own vocabulary is immense, human speech actually consists of about 12-60 units of sound depending, for example, if one is speaking Hawaiian vs English. The English vocabulary consists of several hundred thousand words which are based on the combinations of just 45 different sounds.
Animals too, however, are capable of a vast number of utterances. In fact monkeys and apes employ between 20-25 units of sound, whereas a fox employs 36. However, these animals cannot string these sounds together so as to create a spoken language. Most animals tend to use only a few units of sound at one time which varies depending on their situation, e.g. lost, afraid, playing.
Humans combine these sounds to make a huge number of words. In fact, employing only 13 sound units, humans are able to combine them to form five million word sounds (see Fodor & Katz 1964; Slobin 1971)
PHONEMES
As noted, the auditory areas are specialized to perceive a variety of sounds including those involving temporal sequences and abrupt change sin acoustics--characteristics which also define phonemes, which are the smallest units of sound and which are considered the building blocks of human language. For example, p and b as in bet vs pet are phonemes. When phonemes are strung together as a unit they in turn comprise morphemes. Morphemes such as "cat" are composed of three phonemes, "k,a,t". Hence, phonemes must be arranged in a particular temporal order in order to form a morpheme, and phoneme perception is associated with the auditory area of the left temporal lobe (Ojemann, 1991).
Morphemes in turn make up the smallest unit of meaningful sounds such as those used to signal relationships such as "er" as in "he is older than she." All languages have rules that govern the number of phonemes, their relationships to morphemes and how morphemes may be combined so as to produce meaningful sounds (Fodor & Katz 1964; Slobin 1971).
Each phoneme is composed of multiple frequencies which are in turn processed in great detail once they are transmitted to the superior temporal lobe. As noted, the primary auditory area is tonotopically organized, such that related albeit differing auditory frequencies are analyzed by adjoining cell columns. As also noted, however, it is the left temporal lobe which has been shown to be dominant for the perception of real words, word lists, numbers, syllables, the transitional elements of speech, as well as single phonemes, consonants, and consonant-vowell syllables.
CONSONANTS AND VOWELS
In general, there are two large classes of speech sounds: consonants and vowels. Consonants by nature are brief and transitional and have identification boundaries which are sharply defined. These boundaries enable different consonants to be discerned accurately (Mattingly & Studdert-Kennedy, 1991). Vowels are more continuous in nature and in this regard, the right half of the brain plays an important role in their perception.
Consonants are more important in regard to left cerebral speech perception. This is because they are composed of segments of rapidly changing frequencies which includes the duration, direction and magnitude of sounds segments interspersed with periods of silence. These transitions occur in 50 msecs or less which in turn requires that the left half of the brain take responsibility for perceiving them.
In contrast, vowels consist of a slowly changing or steady frequencies with transitions taking 350 or more msec. In this regard, vowels are more like natural environmental sounds which are more continuous in nature, even those which are brief such as a snap of a twig. They are also more likely to be processed and perceived by the right half of the brain, though the left cerebrum also plays a role in their perception (see chapter 11).
The differential involvement of the right and left hemisphere in processing consonants and vowels is a function of their neuroanatomical organization and the fact that the left cerebrum is specialized for dealing with sequential information. Moreover, the left temporal lobe is able to make fine temporal discriminations with intervals between sounds as small as 50 msec. However, the right hemisphere needs 8-10 times longer and has difficulty discriminating the order of sounds if they are separated by less than 350 msecs.
Hence, consonants are perceived in a wholly different manner from vowels. Vowels yield to nuclei involved in "continuous perception" and are processed by the right (as well as left) half of the brain. Consonants are more a function of "categorical perception" and are processed in the left half of cerebrum. In fact, the left temporal lobe acts on both vowels and consonants during the process of perception so as to sort these signals into distinct patterns of segments via which these sounds become classified and categorized (Joseph 1993).
Nevertheless, be they processed by the right or left brain, both vowels and consonants are significant in speech perception. Vowels are particularly important when we consider their significant role in communicating emotional status and intent.
GRAMMAR & AUDITORY CLOSURE
Despite claims regarding "universal grammars" and "deep structures," it is apparent that human beings speak in a decidedly non-grammatical manner with many pauses, repetitions, incomplete sentences, irrelevant words, and so on. However, this does not prevent comprehension since the structure of the nervous system enables H. sapiens sapiens to perceptually alter word orders so they make sense, and even fill in words which are left out.
For example, when subjects heard a taped sentence in which a single syllable (gis) from the word "legislatures," had been deleted and filled in with static (i.e. le...latures), the missing syllable was not noticed. Rather, all subjects heard "legislatures" (reviewed in Farb 1975)
Similarly, when the word "tress" was played on a loop of tape 120 times per minute (tresstresstress....") subjects reported hearing words such as dress, florists, purse, Joyce, and stress (Farb 1975). In other words they organized these into meaningful speech sounds which were then coded and perceived as words.
The ability to engage in gap filling, sequencing, and to impose temporal order on incoming (supposedly grammatical speech) is important because human speech is not always fluent as many words are spoken in fragmentary form and sentences are usually four words or less . Much of it also consists of pauses and hesitations, "uh" or "err" sounds, stutters, repetitions, and stereotyped utterances, "you know," "like".
Hence, a considerable amount of reorganization as well as filling in must occur prior to comprehension. Therefore, these signals must be rearranged in accordance with the temporal sequential rules imposed by the structure and interaction of Wernicke's area, the inferior parietal lobe and the nervous system -what Noam Chompsky (1957) referred to as "deep structure"- so that they may be understood.
Consciously, however, most people fail to realize that this filling in and reorganization has even occurred, unless directly confronted by someone who claims that she said something she believes she didn't. Nevertheless, this filling in and process of reorganization greatly enhances comprehension and communication.
UNIVERSAL GRAMMARS
Regardless of culture, race, environment, geographical location, parental verbal skills or attention, children the world over go through the same steps at the same age in learning language (Chompsky, 1972). Unlike reading and writing, the ability to talk and understand speech is innate and requires no formal training. One is born with the ability to talk, as well as the ability to see, hear, feel, and so on. However, one must receive training in reading, spelling and mathematics as these abilities are acquired only with some difficulty and much effort. On the other hand, just as one must be exposed to light or he will lose the ability to see complex forms, one must be exposed to language or he will lose the ability to talk or understand human speech.
In his book Syntactic Structures, Chompsky (1957) argues that all human beings are endowed with an innate ability to acquire language as they born able to speak in the same fashion, albeit according to the tongue of their culture, environment and parents. They possess all the rules which govern how language is spoken and they process and express language in accordance with these innate temporal-sequential motoric rules which we know as grammar.
Because they possess this structure, which in turn is imposed by the structure of our nervous system, children are able to learn language even when what they hear falls outside this structure and is filled with errors. That is, they tend to produce grammatically correct speech sequences, even when those around them fail to do so. They disregard errors because they are not processed by their nervous system which acts to either impose order even where there is none, or to alter or delete the message altogether. It is because humans possess these same Wernicke-inferior parietal lobe "deep structures" that speakers are also able to realize generally when a sentence is spoken in a grammatically incorrect fashion.
It is also because apes, monkeys, and dogs and cats do not possess these deep structures that they are unable to speak or produce grammatically complex sequences or gestures. Hence, their vocal production does not become punctuated by temporal-sequential gestures imposed upon auditory input or output by the Language Axis.
LANGUAGE ACQUISITION: FINE TUNING THE AUDITORY SYSTEM
The auditory cortex is organized so as to extract non-random sounds form noise, and in this manner in adaptive for perceiving and detecting animals sounds and human speech (Nelken et al., 1999). However, by time humans have reached adulthood, they have learned to attend to certain language-related sounds and to generally ignore those linguistic features that are not common to speakers native tongue. Some sounds are filtered and ignored as they are irrelevant or meaningless. Humans also lose the ability to hear various sounds because of actual physical changes, such as deterioration and deafness, which occur within the auditory system.
Initially, however, beginning at birth and continuing throughout life there is a much broader range of generalized auditory sensitivity. It is this generalized sensitivity that enables children to rapidly and more efficiently learn a foreign tongue, a capacity that decreases as they age (Janet et al. 1984). It is due, in part, to these same changes that generational conflicts regarding what constitutes "music" frequently arise.
Nevertheless, since much of what is heard is irrelevant and is not employed in the language the child is exposed to, the neurons involved in mediating their perception either drop out and die from disuse, which further restricts the range of sensitivity. This further aids the fine tuning process so that, for example, one's native tongue can be learned (Janet et al. 1984; Joseph 1993).
For example, no two languages have the same set of phonemes. It is because of this that to members of some cultures certain English words, such as pet and bet, sound exactly alike. Non-English speakers are unable to distinguish between or recognize these different sound units. Via this fine tuning process, only those phonemes essential to one's native tongue are attended to.
Language differs not only in regard to the number of phonemes, but the number which are devoted to vowels vs consonants and so on. Some Arabic dialects have 28 consonants and 6 vowels. By contrast, the English language consists of 45 phonemes which include 21 consonants, 9 vowels, 3 semivowels (y, w, r),4 stress, 4 pitches, 1 juncture (pauses between words) and 3 terminal contours which are used to end sentences (Fodor & Katz 1964; Slobin 1971).
It is from these 45 phonemes that all the sounds are derived which make up the infinity of utterances that comprise the English language. However, in learning to attend selectively to these 45 phonemes, as well as to specific consonants and vowels, required that the nervous system become fine tuned to perceiving them while ignoring others. In consequence, those cells which are unused, die (Joseph 1993).
Children are able to learn their own as well as foreign languages with much greater ease than adults because initially infants maintain a sensitivity to a universal set of phonetic categories (e.g. Janet et al. 1984). Because of this they are predisposed to hearing and perceiving speech and anything speech-like regardless of the language employed.
These sensitivities are either enhanced or diminished during the course of the first few years of life so that those speech sounds which the child most commonly hears becomes accentuated and more greatly attended to such that a sharpening of distinctions occurs (Janet et al. 1984). However, this generalized sensitivity in turn declines as a function of acquiring a particular language and presumably the loss of nerve cells not employed (see chapter 15 for related discussion). The nervous system becomes fine tuned so that familiar language-like sounds become processed and ordered in the manner dictated by the nervous system; i.e., the universal grammatical rules common to all languages.
Fine tuning is also a function of experience which in turn exerts tremendous influence on nervous system development and cell death. Hence, by the time most people reach adulthood they have long learned to categorize most of their new experiences into the categories and channels that have been relied upon for decades.
Nevertheless, in consequence of this filtering, sounds that arise naturally within one's environment can be altered, rearranged, suppressed, and thus erased. By fine tuning the auditory system so as to learn culturally significant sounds and so that language can be acquired occurs at a sacrifice. It occurs at the expense of one's natural awareness of their environment and its orchestra of symphonic sounds. In other words (at least from the perspective of the left hemisphere), the fundamental characteristics of reality are subject to language based alterations (Sapir 1966; Whorf 1956).
LANGUAGE AND REALITY
As detailed in chapters 2, 11, and elsewhere (Joseph 1982, 1988a, 1992b, 1993), language is a tool of consciousness, and the linguistic aspects of consciousness are dependent on the functional integrity of the left half of the brain. In that left cerebral conscious experience is, in large part, dependent on and organized in regard to linguistic and temporal-sequential modes of comprehension and expression, language, therefore can shape as well as determine the manner in which perceptual reality is conceived -at least by the left hemisphere.
According the Edward Sapir (1966) "Human beings are very much at the mercy of the particular language which has become the medium of their society...the real world is to a large extent built up on the language habits of the group. No two language are ever sufficiently similar to be considered as representing the same social reality."
According to Benjamin Whorf (1956) "language.... is not merely a reproducing instrument for voicing ideas but rather is itself the shaper of ideas... We dissect nature along lines laid down by language." However, Whorf believed that it was not just the words we used but grammar which has acted to shape human perceptions and thought. A grammatically imposed structure forces perceptions to conform to the mold which gives them not only shape, but direction and order.
Hence, distinctions imposed by temporal order and the employment of linguistically based categories and the labels and verbal associations which enable them to be described can therefore enrich as well as alter thoughts and perceptual reality. This is because language is intimately entwined with conscious experience.
For example, Eskimos possess an extensive and detailed vocabulary which enables them to make fine verbal distinctions between different types of snow, ice, and prey, such as seals. To a man born and raised in Kentucky, snow is snow and all seals may look the same. But if that same man from Kentucky had been raised around horses all his life he may in turn employ a rich and detailed vocabulary so as to describe them, e.g. appaloosa, paint, pony, stallion, and so on. However, to the Eskimo a horse may be just a horse and these other names may mean nothing to him. All horses look the same.
Moreover, both the Eskimo and the Kentuckian may be completely bewildered by the thousands of Arabic words associated with camels, the twenty or more terms for rice used by different Asiatic communities, or the seventeen words the Masai of Africa use to describe cattle.
Nevertheless, these are not just words and names, for each cultural group are also able to see, feel, taste, or smell these distinctions as well. An Eskimo sees a horse but a breeder may see a living work of art whose hair, coloring, markings, stature, tone, height, and so on speak volumes as to its character, future, and genetic endowment.
Through language one can teach others to attend to and to make the same distinctions and to create the same categories. In this way, those who share the same language and cultural group, learn to see and talk about the world in the same way, whereas those speaking a different dialect may in fact perceive a different reality. Thus, the linguistic foundations of conscious experience, and thus linguistic-perceptual consciousness can be shaped by language.
For example, when A.F. Chamberlain (1903), visited the Kootenay and Mohawk Indians of Brittish Columbia during the late 1800s, he noted that they even heard animal and bird sounds differently from him. For example, when listening to some owls hooting, he noted that to him it sounded like "tu-whit-tu-whit-tu-whit," whereas the Indians heard "Katskakitl." However, once he became accustomed to their language and began to speak it, he soon developed the ability to hear sounds differently once he began to listen with his "Indian ears." When listening to a whip poor will, he noted that instead of saying whip-poor-will, it was saying "kwa-kor-yeuh."
Observations such as these thus strongly suggest that if one were to change languages they might change their perceptions and even the expression of their conscious thoughts and attitudes. Consider for example, the results from an experiment reported by Farb (1975). Bilingual Japanese born women married to American Serviceman were asked to answer the same question in English and in Japanese. The following responses were typical.
"When my wishes conflict with my family's..."
"....it is a time of great unhappiness (Japanese)
....I do what I want. (English)
"Real friends should...."
"...help each other." (Japanese)
"...be very frank." (English)
Obviously, language does not shape all attitudes and perceptions. Moreover, language is often a consequence of these differential perceptions, which in turn requires the invention of new linguistic labels so as to describe these new experiences. Speech of course is also filtered through the personality of the speaker, whereas the listener is also influenced by their own attitudes, feelings, beliefs, prejudices and so on, all of which can affect what is said, how it is said, and how it is perceived and interpreted (Joseph 1993).
In fact, regardless of the nature of a particular experience, be it visual, olfactory or sexual, language not only influences perceptual and conscious experiences but even the ability to derive enjoyment from them, for example, by labeling them cool, hip, sexy, bad, or sinful, and by instilling guilt or pride. In this manner, language serves not only to label and filter reality, but affects one's ability to enjoy it.
SPATIAL LOCALIZATION, ATTENTION & ENVIRONMENTAL SOUNDS
In conjunction with the inferior colliculus and the frontal lobe (Graziano et al., 1999), and due to bilateral auditory input, the primary auditory area plays a significant role in orienting to and localizing the source of various sounds (Sanchez-Longo & Forster, 1958); for example, by comparing time and intensity differences in the neural input from each ear. A sound arising from one's right will reach and sound louder to the right ear as compared to the left.
Indeed, among mammals, a considerable number of auditory neurons respond or become highly excited only in response to sounds from a particular location (Evans & Whitfield, 1968). Moreover, some of these neurons become excited only when the subject looks at the source of the sound (Hubel et al., 1959). Hence, these neurons act so that location may be identified and fixated upon. In addition to the frontal lobe (Graziano et al., 1999) these complex interactions probably involve the parietal area (7), as well as the midbrain colliculi and limbic system. As based on lesions studies in humans, the right temporal lobe is more involved than the left in discerning location (Nunn et al., 1999; Penfield & Evans, 1934; Ploner et al., 199; Shankweiler, 1961).
There is also some indication that certain cells in the auditory area are highly specialized and will respond only to certain meaningful vocalizations (Wollberg & Newman, 1972). In this regard they seemed to be tuned to respond only to specific auditory parameters so as to identify and extract certain meaningful features, i.e. feature detector cells. For example, some cells will respond to cries of alarm and sounds suggestive of fear or indicating danger, whereas others will react only to specific sounds and vocalizations.
Nevertheless, although the left temporal lobe appears to be more involved in extracting certain linguistic features and differentiating between semantically related sounds (Schnider et al. 2004), the right temporal region is more adept at identifying and recognizing acoustically related sounds and non-verbal environmental acoustics (e.g. wind, rain, animal noises), prosodic-melodic nuances, sounds which convey emotional meaning, as well as most aspects of music including temp and meter (Heilman et al. 1975, 1984; Joseph, 1988a; Kester et al. 1991; Schnider et al. 2004; Spinnler & Vignolo 1966).
Indeed, the right temporal lobes spatial-localization sensitivity coupled with its ability to perceive and recognize environmental sounds no doubt provided great survival value to early primitive man and woman. That is, in response to a specific sound (e.g. a creeping predator), one is able to immediately identify, localize, locate, and fixate upon the source and thus take appropriate action. Of course, even modern humans relie upon the same mechanisms to avoid cars when walking across streets or riding bicycles, or to ascertain and identify approaching individuals, etc.
HALLUCINATIONS
Electrical stimulation of Heschyl's gyrus produces elementary hallucinations (Penfield & Jasper, 1954; Penfield & Perot, 1963). These include buzzing, clicking, ticking, humming, whispering, and ringing, most of which are localized as coming from opposite side of the room. Tumors involving this area also give rise to similar, albeit transient hallucinations, including tinnitus (Brodal, 1981). Patients may complain that sounds seem louder and/or softer than normal, closer and/or more distant, strange or even upleasant (Hecaen & Albert, 1978). There is often a repetitive quality which makes the experience even more disagreeable.
In some instances the hallucination may become meaningful. These include the sound of footsteps, clapping hands, or music, most of which seem (to the patient) to have an actual external source.
Penfield and Perot (1963) report that electrical stimulation of the superior temporal gyrus, the right temporal lobe in particular results in musical hallucinations. Patients with tumors and seizure disorders, particularly those involving the right temporal region, may also experience musical halluciantions. Frequenty the same melody is heard over and over. In some instances patients have reported the sound of singing voices and individual instruments may be heard (Hecaen & Albert, 1978).
Conversely, it has been frequently reported that lesions or complete surgical destruction of the right temporal lobe significantly impaires the ability to name or recognize melodies and musical passages. It also disrupts time sense, the perception of timbre, loudness, and meter (Chase, 1967; Joseph, 1988a; Kester et al. 1991; Milner, 1962; Shankweiler, 1966).
Auditory verbal hallucinations seem to occur with right or left temporal destruction or stimulation (Hecaen & Albert, 1978; Penfield & Perot, 1963; Tarachow, 1941) --although left temporal involvement is predominant. The hallucination may involve single words, sentences, commands, advice, or distant conversations which can't quite be made out. According to Hecaen and Albert (1978), verbal hallucinations may precede the onset of an aphasic disorder, such as due to a developing tumor or other destructive process. Patients may complain of hearing "distorted sentences", "incromprehensible words" etc.
CORTICAL DEAFNESS
In some instances, such as due to middle cerebral artery stroke, the primary auditory receiving areas of the right or left cerebral hemisphere and/or the unerlying "white matter" fiber tracts may be destroyed. This results in a disconnection syndrome such that sounds relayed from the thalamus cannot be received or anlayzed by the temporal lobe. In some cases, however, the strokes may be bilateral. When both primary auditory receiving areas and their subcortical axonal connections have been destroyed the patient is said to be suffering from cortical deafness (Goodglass & Kaplan, 1999; Tanaka et al. 1991).
However, sounds continue to be processed subcortically --much like cortical blindness. Hence the ability to hear sounds per se, is retained. Nevertheless, since the sounds which are heard are not received neocortically and thus cannot be transmitted to the adjacent associaiton areas, sounds become stripped of meaning. That is, meaning cannot be extracted or assigned and the patient becomes agnosic for auditory stimuli (Albert et al. 1972; Schnider et al. 2004; Spreen et al. 1965). Rather, only differences in intensity are discernable --much like cortical blindness.
When lesions are bilateral, patients cannot respond to questions, do not show startle responses to loud sounds, lose the ability to discern the melody for music, cannot recognize speech or environmental sounds, and tend to experience the sounds they do hear as distorted and disagreeable, e.g. like the baning of tin cans, buzzing and roaring, etc. (Albert et al. 1972; Auerbach et al., 1982; Earnest et al. 1977; Kazui et al. 2010; Mendez & Geehan, 1988; Reinhold, 1950; Tanaka et al. 1991).
Commonly such patients also experience difficulty discriminating sequences of sound, detecting difference in temporal patterning, and determining sound duration wheareas intensity discriminations are better preserved. For example, when a 66 year old right handed male suffering from bitemporal subcortical lesions, "woke up in the morning and turned on the television, he found himself unable to hear anything but buzzing noises. He then tried to talk to himself, saying "This TV is broken." However, his voices sounded only as noise to him. Although the patient could hear his wife's voice, he could not interpret the meaning of her speech. He was also unable to identify many environmental sounds" (Kazui, et al. 2010; p. 477).
Nevertheless, individuals who are cortically deaf are not aphasic (e.g. Kazui et al. 2010. They can read, write, speak, comprehend pantomime, and are fully aware of their deficit. However, afflicted individuals may also display auditory inattention (Hecaen & Albert, 1978) and a failure to respond to loud sounds. Nevertheless, although not aphasic, per se, speech is sometimes noted to be hypophonic and contaminated by occasional literal paraphasias.
In some instances, rather than bilateral, a destructive lesion may be limited to the primary receving area of just the right or left cerebral hemisphere. These patient's are not considered cortically deaf. However, when the auditory receiving area of the left temporal lobe is destroyed the patient suffers from a condition referred to as pure word deafness. If the lesion is in the right temporal receiving area, the patient is more likely to suffer a non-verbal auditory agnosia (Schnider et al. 2004).
PURE WORD DEAFNESS
With a destructive lesion involving the left auditory receiving area, Wernicke's area becomes disconnected from almost all sources of acoustic input and patients are unable to recognize or perceive the sounds of language, be it sentences, single words, or even single letters (Hecaen & Albert, 1978). All other aspects of comprehension are preserved, including reading, writing, and expressive speech.
Moreover, if the right temporal region is spared, the ability to recognize musical and environmental sounds is preserved. However, the ability to name or verbally describe them is impaired --due to disconnection and the inability of the right hemisphere to talk.
Pure word deafness is most common with bilateral lesions in which case environmental sound recognition is also effected (e.g. Kazui et al. 2010). In these instances the patient is considered cortically deaf. Pure word deafness is more common with bilateral lesions simply because this prevents the any remaining intact auditory areas in the left hemisphere from receiving auditory input from the right temporal lobe via the corpus callosum.
Pure word deafness, when due to a unilateral lesion of the left temporal lobe, is partly a consequence of an inability to extract temporal-sequential features from incoming sounds. Hence, linguistic messages cannot be recognized. However, pure word deafness can sometimes be partly overcome if the patient is spoken to in an extremely slowed manner (Albert & Bear, 2014). The same is true of those with Wernicke's aphasia.
AUDITORY AGNOSIA
An individual with cortical deafness, due to bilateral lesions suffers from a generalized auditory agnosia involving words and non-linguistic sounds. However, in many instances an auditory agnosia, with preserved perception of language may occur with lesions restricted to the right temporal lobe (Fujii et al., 2010). In these instances, an indvidual loses the capability to correctly discern environmental (e.g. birds singing, doors closing, keys jangling) and acoustically related sounds, emotional-prosodic speech, as well as music (Nielsen, 1946; Ross, 1993; Samson & Zattore, 1988; Schnider et al. 2004; Spreen et al. 1965; Zatorre & Hapern, 1993).
These problems are less likely to come to the attention of a physician unless accompanied by secondary emotional difficulties. That is, most individuals with this disorder, being agnosic, would not know that they have a problem and thus would not complain. If they are their families notice (for example, if a patient does not respond to a knock on the door) the likelyhood is that the problem will be attributed to faulty hearing or even forgetfulness.
However, because such individuals may also have difficulty discerning emotional- melodic nuances, it is likely that they will misperceive and fail to comprehend a variety of paralinguistic social-emotional messages; a condition referred to as social-emotional agnosia (Joseph, 1988a) and phonagnosia (van Lancker, et al., 1988). This includes difficulty correctly identifying the voices of loved ones or friends, or discerning what others may be implying, or in appreciating emotional and contextual cues, including variables such as sincerity or mirthful intonation. Hence, a host of behavioral difficulties may arise (see chapter 10).
For example, a patient may complain that his wife no longer loves him, and that he knows this from the sound of her voice. In fact, a patient may notice that the voices of friends and family sound in some manner different, which, when coupled with difficulty discerning nuances such as humor and friendliness may lead to the development of paranoia and what appears to be delusional thinking. Indeed, unless appropriately diagnoses it is likely that the patients problem will feed upon and reinforce itself and grow more severe.
It is important to note that rather than completely agnosic or word deaf, patients may suffer from only partial deficits. In these isntances they may seem to be hard of hearing, frequently misinterpret what is said to them, and/or slowly develop related emotional difficulties.
THE AUDITORY ASSOCIATION AREAS
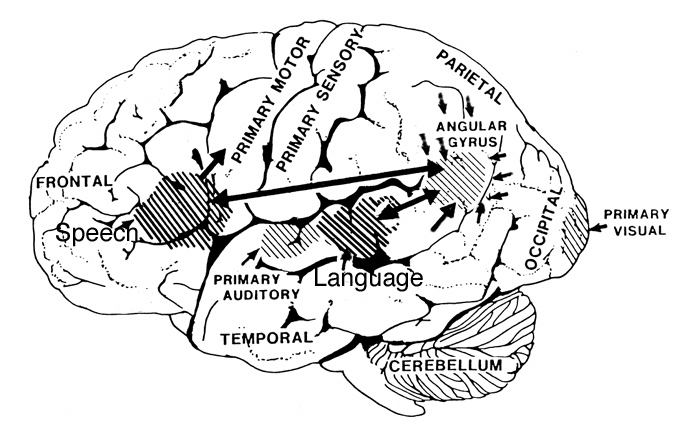
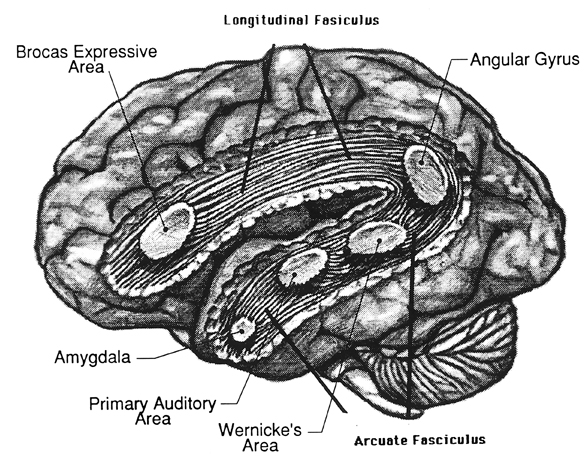
The auditory area although originating in the depths of the superior temporal lobe extends in a continuous belt-like fashion posteriorly from primary and association (e.g. Wernicke's) area toward the inferior parietal lobule, and via the arcuate fasciculus onward toward Broca's area. Indeed, in the left hemisphere, this massive rope of interconnections forms an Axis such that Wernickes Area, the inferior parietal lobule, and Broca's area. These areas often become activated in parallel or simultaneously during language tasks, and together, are able to mediate the perception and expression of most forms of language and speech (Joseph, 1982, Goodglass & Kaplan, 2000; Ojemann, 1991).
The rope-like arcuate and inferior and superior fasciculi are bidirectional fiber pathways, however, that run not only from Wernickes through to Broca's area but extends inferiorly deep into the temporal lobe where contact is established with the amygdala. Hence, via these connections auditory input comes to be assigned emotional-motivational significance, whereas verbal output becomes emotionally-melodically colored . Within the right hemisphere, these interconnections which include the amygdala appear to be more extensively developed.
WERNICKE'S AREA
Following the analysis performed in the primary auditory receiving area, auditory information is transmitted to the immediately adjacent association cortex (Brodmanns area 22), where more complex forms of processing take place. In both hemispheres this region partly surrounds the primary area and then extends posteriorly merging with the inferior parietal lobule with which it maintains extensive interconnections. Within the left hemisphere the more posterior portion of area 22, and part of area 42 corresponds to Wernicke's area.
Wernickes area, and the corresponding region in the right hemisphere are not merely auditory association areas as they also receive a convergence of fibers from the somesthetic and visual association cortices (Jones & Powell, 1970; Zeki, 1978b). These interlinking pathways include the inferior and middle temporal lobes which are also multi-modal areas concerned with language, somesthesis, and complex visual functioning (Buchel et al., 1998; Luders et al., 1986; Nobre et al., 2004; Price, 1997), and the immediately adjacent inferior parietal lobule which becomes active when viewing words (Bookheimer, et al., 1995; Vandenberghe, et al., 1996; , Menard, et al., 1996; Price, 1997) when performing syllable judgements (Price, 1997), and when reading ( Bookheimer, et al., 1995; Menard, et al., 1996; Price, et al., 1996).
The auditory association area (area 22) also receives fibers from the contralateral auditory association area via the corpus callosum and anterior commissure and projects to the frontal convexity and orbital region, the frontal eye fields, and cingulate gyrus (Jones & Powell, 1970). Hence, Wernicke's area receives input from a variety of convergence zones, and is involved in multimodal as well as auditory associational analysis and becomes highly active during a variety of language tasks (Buchel et al., 1998; Price, 1997).
Broadly considered, Wernicke's area encompasses a large expanse of tissue that extends from the posterior superior and middle temporal lobe to the IPL and up a over the parietal operculum, around the sylvian fissure, extending just beyond the supramarginal gyrus. Electrical stimulation, the surgical destruction, or lesions of this region results in significant language impariments (Kertesz, 2009; Penfield & Roberts, 1959; Ojemann, 1991). However, this vast expanse of cortex is actually made up of a mosaic of speech area, each concerned with different aspects of language, including comprehesion, word retrieval, naming, verbal memory, and even expressive speech.
For example, only 36% of stimulation sites in the classically defined Wernicke's area (anterior to the IPL), interfere with naming, whereas phoneme identification is significantly impaired (Ojemann, 1991). By contrast, and as noted above, the IPL (which is an extension of Wernicke's area) becomes highly active when retrieving words or engaged in naming. In this regard, the IPL and Wernicke's area interact so as to comprehend and express the sounds and words of language--all of which is then transmitted via the arcuate fasiculus to Broca's area.
RECEPTIVE APHASIA
When the posterior portion of the left auditory association area is damaged there results severe receptive aphasia i.e. Wernicke's aphasia. Individuals with Wernickes aphasia, in addition to severe comprehension deficits usually suffer abnormalities involving expressive speech, reading, writing, repeating, word finding, etc. Spontaneous speech, however, is often fluent, and sometimes hyperfluent such that they speak at an increased rate and seem unable to bring sentences to an end --as if the temporal-sequential separations between words have been extremely shortened or in some instances abolished. In addition, many of the words spoken are contaminated by neologistic and paraphasic distortions. As such, what they say is often incomprehensible (Chirstman 2004; Goodglass & Kaplan 1999; Hecaen & Albert, 1978). Hence, this disorder has also been referred to as fluent aphasia.
Individuals with Wernicke's aphasia, however, are still able to perceive the temporal-sequential pattern of incoming auditory stimuli to some degree (due to preseveration of the primary region). Nevertheless, they are unable to perceive spoken words in their correct order, cannot identify the pattern of presentation (e.g. two short and three long taps) and become easily overwhelmed (Hecaen & Albert, 1978; Luria, 1980).
Patients with Wernicke's aphasia, in addition to other impairments, are necessarily "word deaf". As these individuals recover from their aphasia, word deafness is often the last symptom to disapear (Hecaen & Albert, 1978).
THE MELODIC-INTONATIONAL AXIS
It has been consistently demonstrated among normals (such as in dichtotic listening studies), that the right temporal lobe (left ear) predominantes in the perception of timbre, chords, tone, pitch, loudness, melody, and intensity --the major components (in conjuction with harmony) of a musical stimulus (chapter 10). For example, when listening to Bach (the third movement of Bach's Italian concerto), the right temporal lobe becomes highly active, whereas when performing scales activity increases in the left temporal lobe (Parsons & Fox, 1997). Likewise, Evers and colleagues (1999) in evaluating cerebral blood velocity, found that a right hemisphere increase in blood flow when listening to harmony (but not rhythm), among non-musicians in general, and especially among females. Rhythm increased left hemisphere activity (Evers et al., 1999). Hence, the left hemisphere is clearly dominant in regard to the rhythmical and temporal sequential aspects of a musical stimulus (Evers et al., 1999; Parsons & Fox, 1997).
In part, it is due to its dominance for perceiving melodic information that the right temporal lobe becomes activated when engaged in a variety of language tasks. For example, the right temporal and parietal areas are activated when reading (Bottini et al., 2004; Price et al., 1996), and the right temporal lobe becomes highly active when engage in interpreting the figurative aspects of language (Bottini et al., 2004).
When the right temporal lobe is damaged (e.g. right temporal lobectomy, right amygdalectomy) there results a disrupts in time sense, rhythm, the ability to sing, carry a tune, perceive, recognize or recall tones, loudness, timbre, and melody. Similarly, the ability to recognize even familiar melodies and the capacity to obtain pleasure while listening to music is abolished or disrupted or significantly reduced; a condition referred to as amusia.
For example, a woman described by Takeda and colleagues (2010) and who was described as an expert singer of traditional Japanese songs, and who would accompany them on an instrument referred to as a samisen, lost this ability following a hemorrhagic stroke of the of the right superior gyrus including Heschl's gyrus. Although she was able to accurately produce the rhythmic aspects of music, melody and pitch were abolished.
In addition, lesions involving the right temporal-parietal area, have been reported to significantly impair the ability to perceive and identify environmental sounds, comprehend or produce appropriate verbal prosody, emotional speech, or to repeat emotional statements (Joseph, 1988a; Ross, 1993; van Lancker et al., 1988). Indeed, when presented with neutral sentences spoken in an emotional manner, right temporal-parietal damage has been reported to disrupt the perception and comprehension of emotional prosody regardless of its being positive or negative in content (see chapter 10).
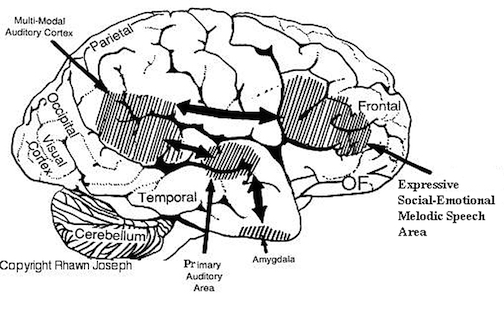
Hence, the right temporal-parietal area is involved in the perception, identification, and comprehension of environmental and musical sounds and various forms of melodic and emotional auditory stimuli, and probably acts to prepare this information for expression via transfer to the right frontal convexity which is dominant regarding the expression of emotional-melodic and even environmental sounds. Indeed, it appears that an emotional-melodic-intonational Axis, somewhat similar to the Language Axis in anatomical design is maintained within the right hemisphere (Joseph 1982, 1988a; Gorelick & Ross, 1987; Ross, 1993).
When the posterior portion of the Melodic-Emotional Axis is damaged, the ability to comprehend or repeat melodic-emotional vocalizations in disrupted. Such patients are thus agnosic for non-linguistic sounds. With right frontal convexity damage speech becomes bland, atonal, and monotone.
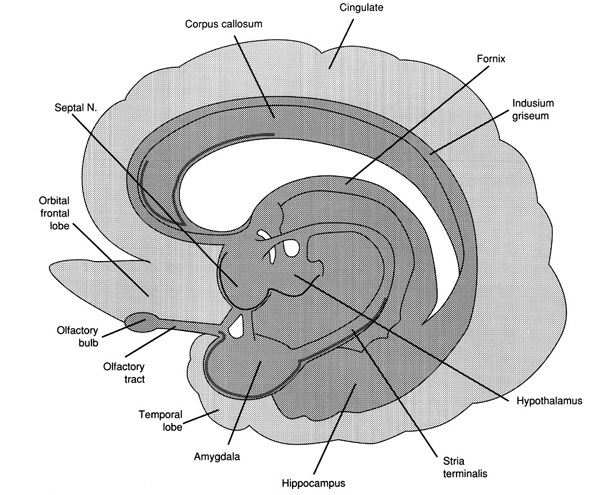
THE AMYGDALA.
As detailed in chapters 13 and 15, the right cerebral hemisphere appears to maintain more extensive as well as bilateral interconnections with the limbic system. Indeed, the limbic system also appears to be lateralized in regard to certain aspects of emotional functioning such that the right amygdala, hippocampus and hypothalamus seem to exert dominant influences.
As noted, the arcuate fasciculus extends from the amygdala (which is buried within the anterior-inferior temporal lobe) through the auditory association area and inferior parietal region and into the frontal convexity. It is possibly through these interconnections that emotional colorization is added to neocortical acoustic perceptions as well as sounds being prepared for expression. In fact, the human amygdala can produce as well as perceive emotional vocalizations (Halgren, 1992; Heit, Smith, & Halgren, 1988). Moreover, when the right amygdala has been destroyed or surgically removed, the ability to sing as well as to properly intonate is altered. In this regard, the amygdala should be considered part of the melodic-intonational axis of the right hemisphere as it not only subcortically responds to and analyzes environmental sounds and emotional vocalizations but imparts emotional significance to auditory input and output processed and expressed at the level of the neocortex.
Nevertheless, it is possible that emotional-prosodic intonation is imparted directly to speech variables as they are being organized for expression within the left hemisphere. That is, although the right hemisphere is dominant in regard to melodic-emotional vocalizations, the two amygdalas are in direct communication via the anterior commissure. Hence, although originating predominantly within the right amygdala/hemisphere, these influences can be directly transmitted to the left half of the brain via the left amygdala and through anterior commissure and via the arcuate fasciculus which transmits this data into the linguistic stream of the Language Axis.
REFERENCES